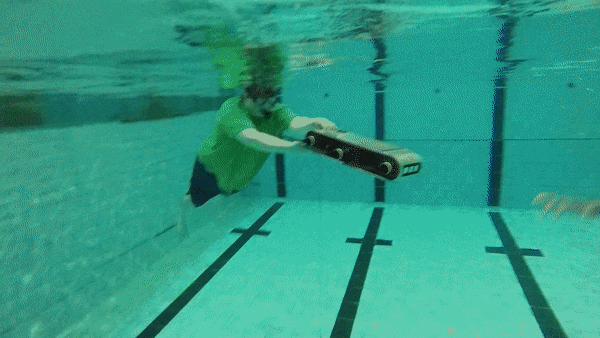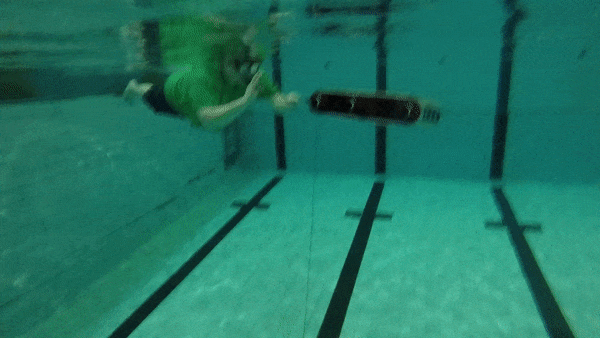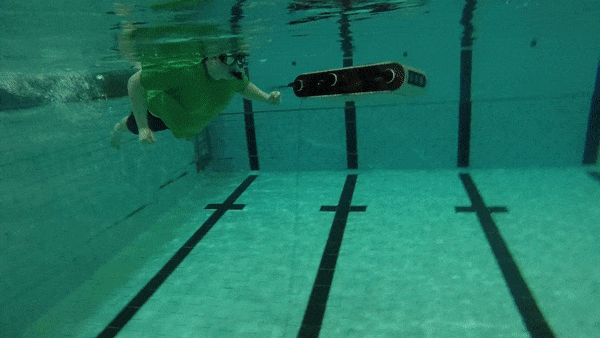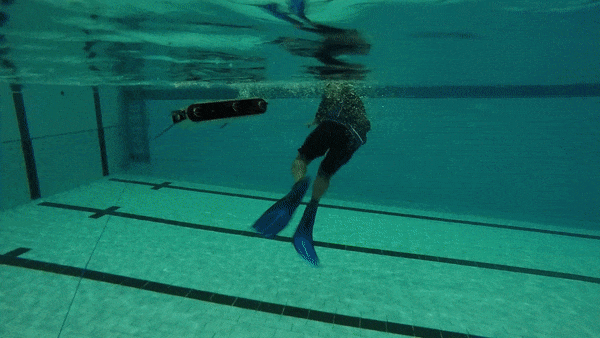SVAM: Saliency-guided Visual Attention Modeling
Paper (RSS 2022) ArXiv Bibliography GitHub USOD Test Dataset Video Demo
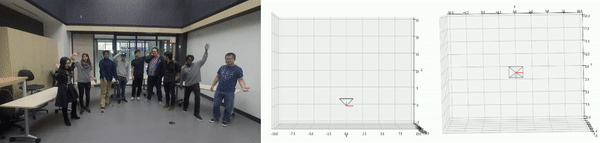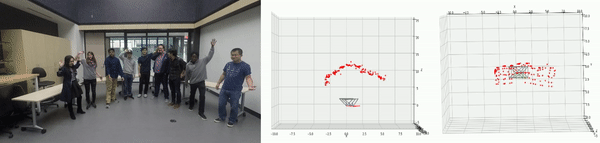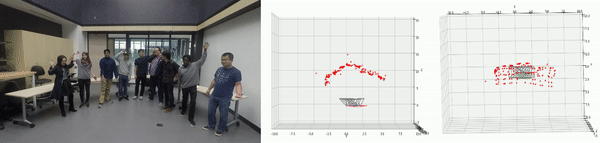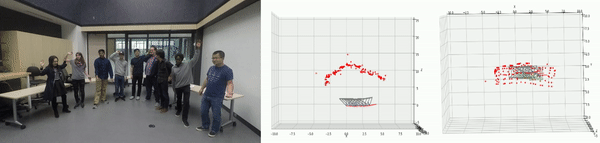
Where to look?— is an intriguing problem of computer vision that deals with finding interesting or salient pixels in an image/video. As seen in this GANGNAM video!, the problem of Salient Object Detection (SOD) aims at identifying the most important or distinct objects in a scene. It is a successor to the human fixation prediction problem that aims to highlight pixels that human viewers would focus on at first glance.

For visually-guided robots, the SOD capability enables them to model spatial attention to eventually make important navigation decisions. In this project, we present a holistic approach to saliency-guided visual attention modeling (SVAM) for use by autonomous underwater robots. Our proposed model, named SVAM-Net, integrates deep visual features at various scales and semantics for effective SOD in natural underwater images. The SVAM-Net architecture is configured in a unique way to jointly accommodate bottom-up and top-down learning within two separate branches of the network while sharing the same encoding layers. We design dedicated spatial attention modules (SAMs) along these learning pathways to exploit the coarse-level and top-level semantic features for SOD at four stages of abstractions.
Specifically, the bottom-up pipeline extracts semantically rich features from early encoding layers, which facilitates an abstract yet accurate saliency prediction at a fast rate; we denote this decoupled bottom-up pipeline as SVAM-NetLight. In addition, a residual refinement module (RRM) ensures fine-grained saliency estimation through the deeper top-down pipeline. Check out this repository for the detailed SVAM-Net model architecture and its holistic learning pipeline.
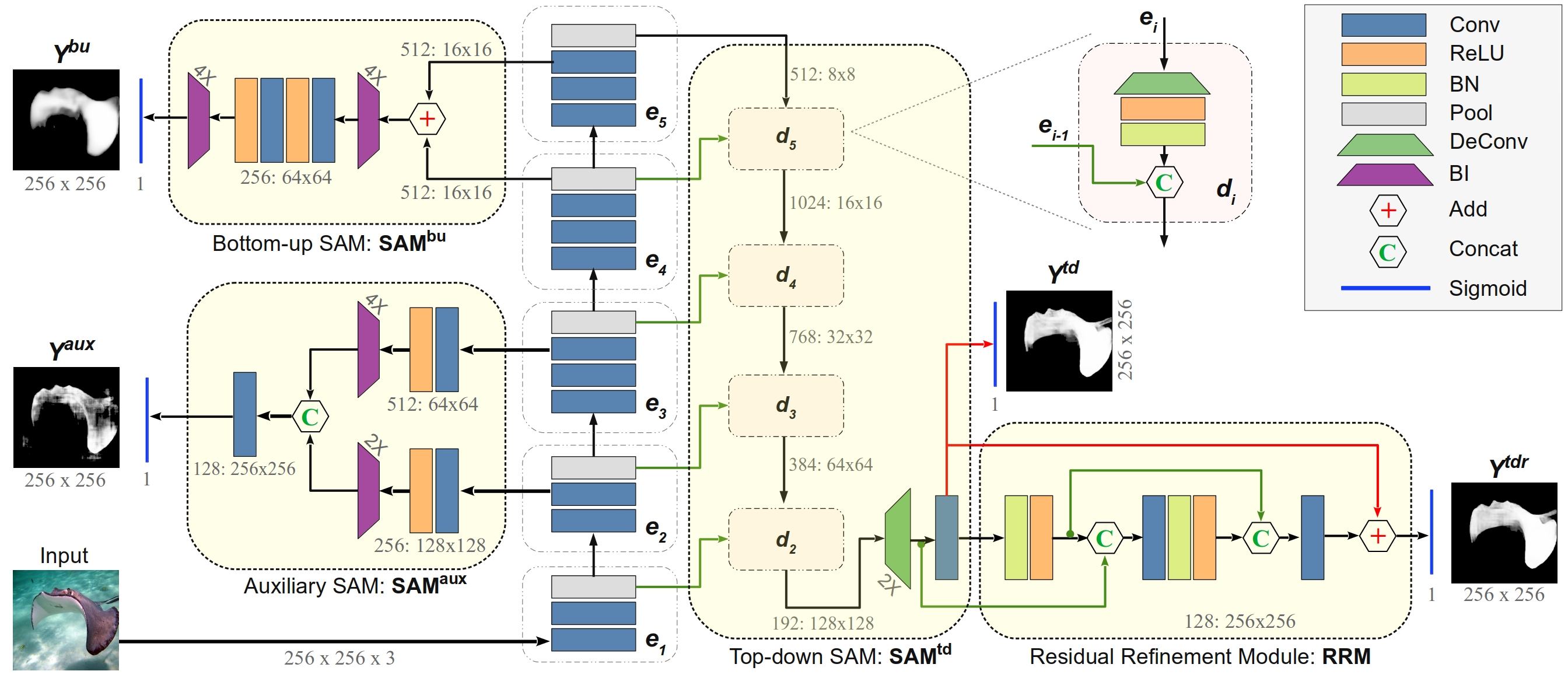

In the implementation, we incorporate comprehensive end-to-end supervision of SVAM-Net by large-scale diverse training data consisting of both terrestrial and underwater imagery. Subsequently, we validate the effectiveness of its learning components and various loss functions by extensive ablation experiments. In addition to using existing datasets, we release a new challenging test set named USOD for the benchmark evaluation of SVAM-Net and other underwater SOD models. By a series of qualitative and quantitative analyses, we show that SVAM-Net provides SOTA performance for SOD on underwater imagery, exhibits significantly better generalization performance on challenging test cases than existing solutions, and achieves fast end-to-end inference on single-board devices. Moreover, we demonstrate that a delicate balance between robust performance and computational efficiency makes SVAM-NetLight suitable for real-time use by visually-guided underwater robots. Please refer to the paper for detailed results; a video demonstration can be seen here.
Update: accepted for publication at the RSS 2022